Databricks Stock Chart
Databricks Stock Chart - While databricks manages the metadata for external tables, the actual data remains in the specified external location, providing flexibility and control over the data storage. Actually, without using shutil, i can compress files in databricks dbfs to a zip file as a blob of azure blob storage which had been mounted to dbfs. The datalake is hooked to azure databricks. Databricks is smart and all, but how do you identify the path of your current notebook? The requirement asks that the azure databricks is to be connected to a c# application to be able to run queries and get the result all from the c#. This will work with both. It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. It is helpless if you transform the value. Also i want to be able to send the path of the notebook that i'm running to the main notebook as a. The guide on the website does not help. Actually, without using shutil, i can compress files in databricks dbfs to a zip file as a blob of azure blob storage which had been mounted to dbfs. I am able to execute a simple sql statement using pyspark in azure databricks but i want to execute a stored procedure instead. The datalake is hooked to azure databricks. It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. While databricks manages the metadata for external tables, the actual data remains in the specified external location, providing flexibility and control over the data storage. Also i want to be able to send the path of the notebook that i'm running to the main notebook as a. Here is my sample code using. I want to run a notebook in databricks from another notebook using %run. Databricks is smart and all, but how do you identify the path of your current notebook? It is helpless if you transform the value. Below is the pyspark code i tried. First, install the databricks python sdk and configure authentication per the docs here. I am able to execute a simple sql statement using pyspark in azure databricks but i want to execute a stored procedure instead. I want to run a notebook in databricks from another notebook using %run. Actually, without using shutil,. I am able to execute a simple sql statement using pyspark in azure databricks but i want to execute a stored procedure instead. I want to run a notebook in databricks from another notebook using %run. This will work with both. Create temp table in azure databricks and insert lots of rows asked 2 years, 7 months ago modified 6. This will work with both. I am able to execute a simple sql statement using pyspark in azure databricks but i want to execute a stored procedure instead. Databricks is smart and all, but how do you identify the path of your current notebook? Actually, without using shutil, i can compress files in databricks dbfs to a zip file as. The guide on the website does not help. Below is the pyspark code i tried. Create temp table in azure databricks and insert lots of rows asked 2 years, 7 months ago modified 6 months ago viewed 25k times Actually, without using shutil, i can compress files in databricks dbfs to a zip file as a blob of azure blob. Actually, without using shutil, i can compress files in databricks dbfs to a zip file as a blob of azure blob storage which had been mounted to dbfs. The datalake is hooked to azure databricks. I want to run a notebook in databricks from another notebook using %run. This will work with both. Also i want to be able to. Databricks is smart and all, but how do you identify the path of your current notebook? Create temp table in azure databricks and insert lots of rows asked 2 years, 7 months ago modified 6 months ago viewed 25k times I want to run a notebook in databricks from another notebook using %run. This will work with both. The datalake. This will work with both. While databricks manages the metadata for external tables, the actual data remains in the specified external location, providing flexibility and control over the data storage. It is helpless if you transform the value. It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. Also i want to. The requirement asks that the azure databricks is to be connected to a c# application to be able to run queries and get the result all from the c#. It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. Actually, without using shutil, i can compress files in databricks dbfs to a. I am able to execute a simple sql statement using pyspark in azure databricks but i want to execute a stored procedure instead. First, install the databricks python sdk and configure authentication per the docs here. Also i want to be able to send the path of the notebook that i'm running to the main notebook as a. Below is. The guide on the website does not help. Databricks is smart and all, but how do you identify the path of your current notebook? This will work with both. The datalake is hooked to azure databricks. Actually, without using shutil, i can compress files in databricks dbfs to a zip file as a blob of azure blob storage which had. While databricks manages the metadata for external tables, the actual data remains in the specified external location, providing flexibility and control over the data storage. This will work with both. I am able to execute a simple sql statement using pyspark in azure databricks but i want to execute a stored procedure instead. The guide on the website does not help. Actually, without using shutil, i can compress files in databricks dbfs to a zip file as a blob of azure blob storage which had been mounted to dbfs. Create temp table in azure databricks and insert lots of rows asked 2 years, 7 months ago modified 6 months ago viewed 25k times Here is my sample code using. Databricks is smart and all, but how do you identify the path of your current notebook? The datalake is hooked to azure databricks. Below is the pyspark code i tried. It is helpless if you transform the value. Also i want to be able to send the path of the notebook that i'm running to the main notebook as a.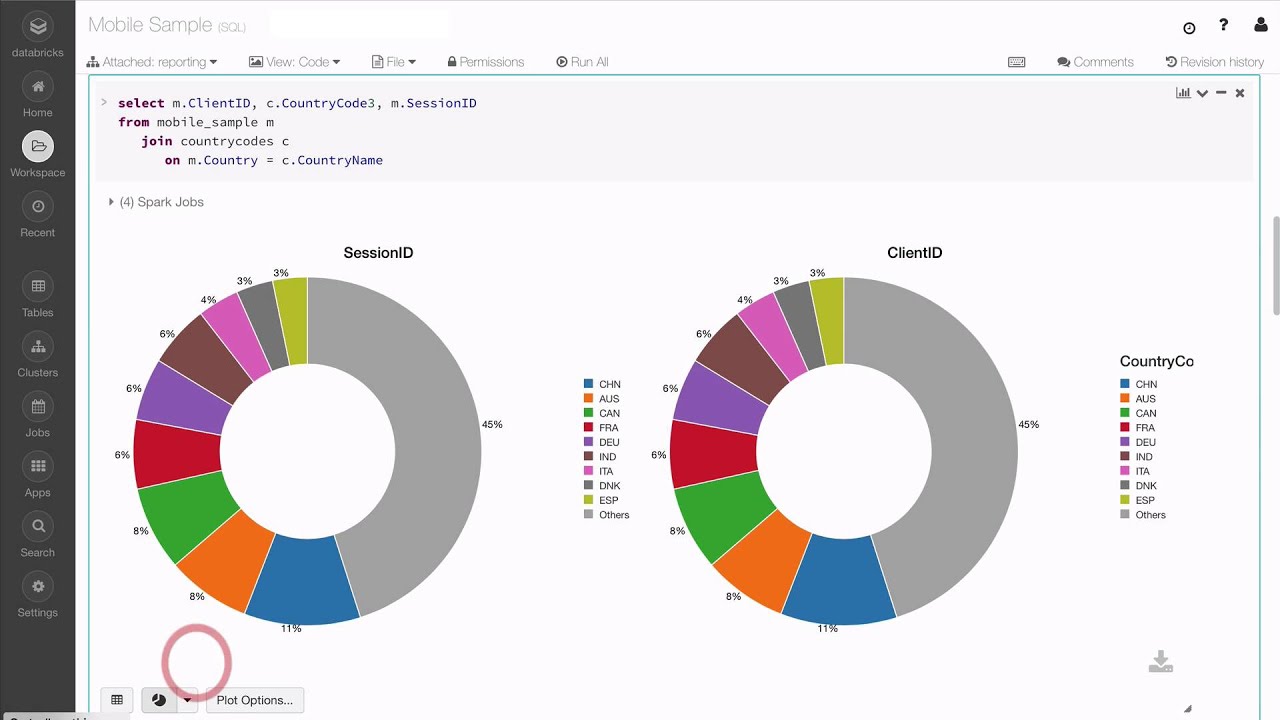
Visualizations in Databricks YouTube
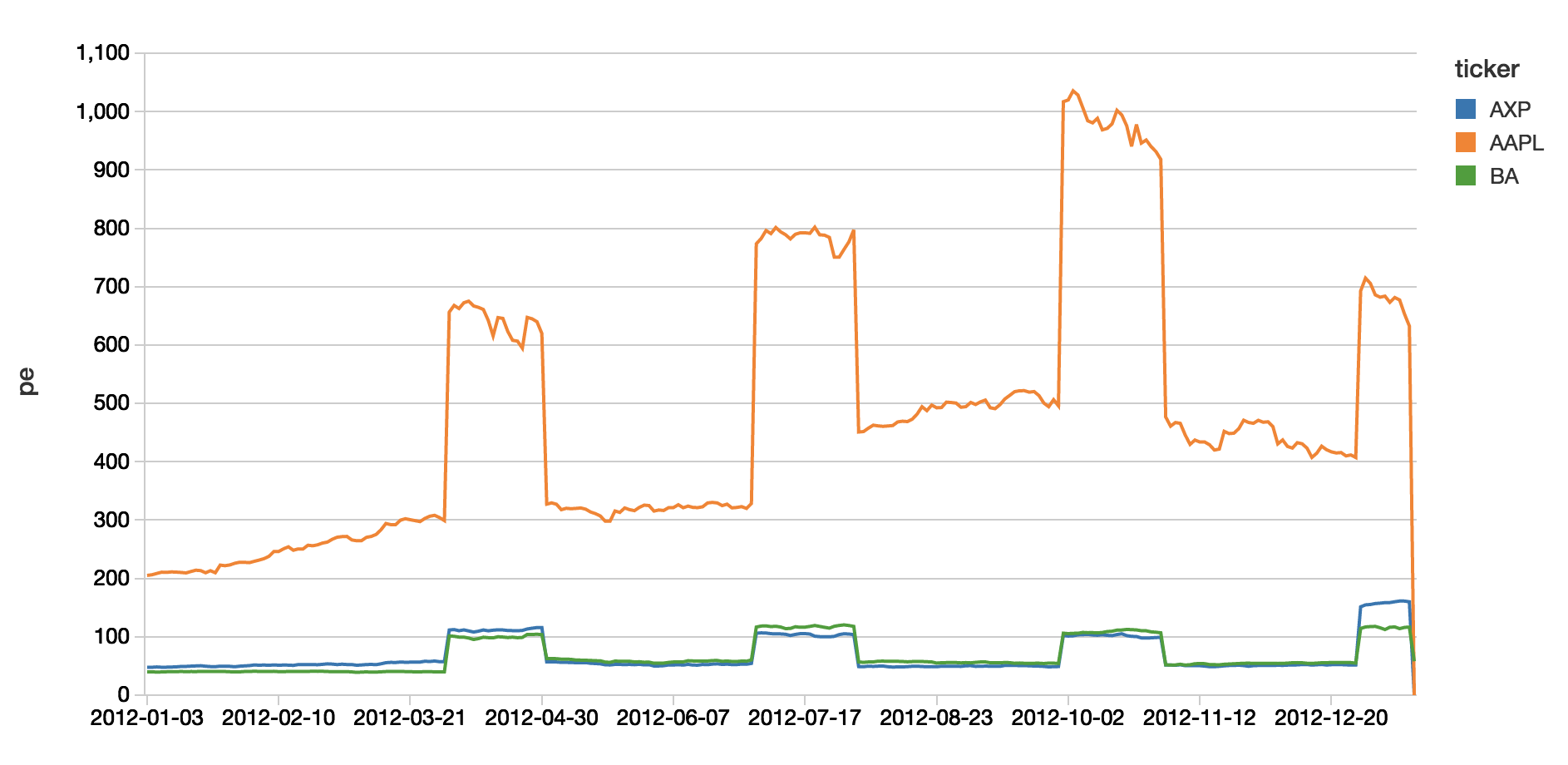
Simplify Streaming Stock Data Analysis Databricks Blog
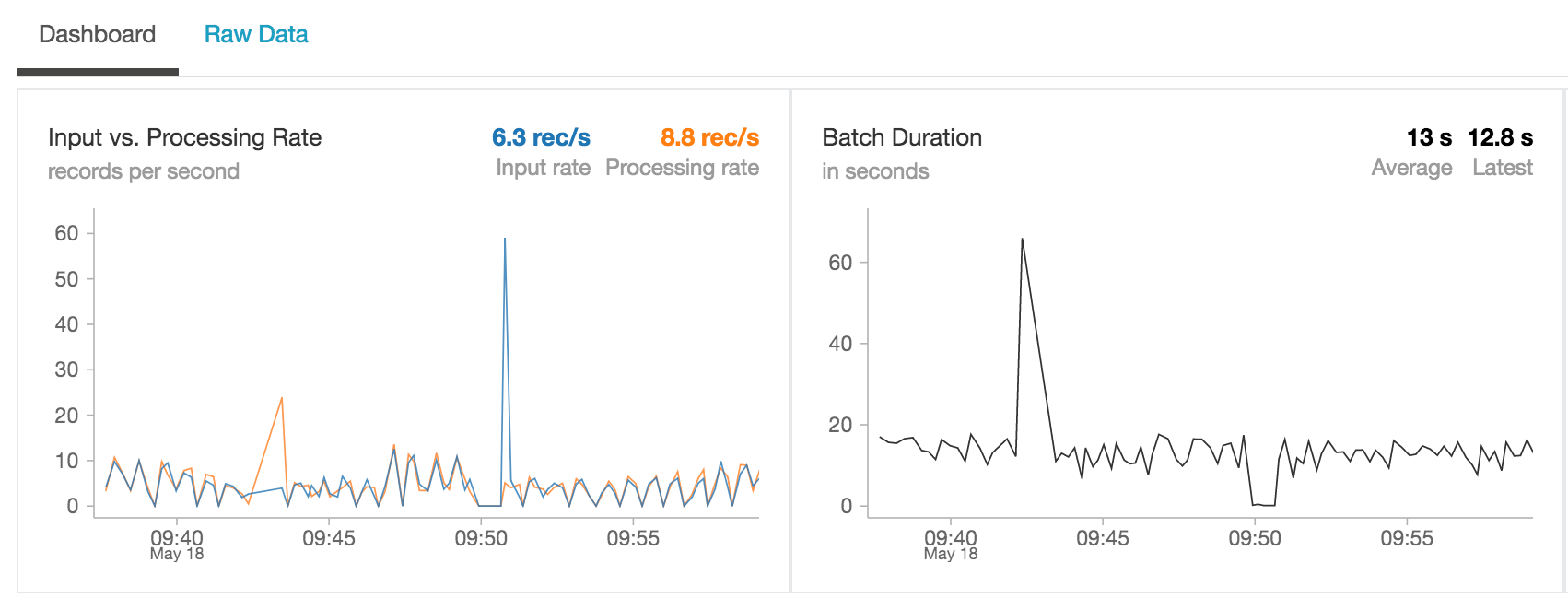
Simplify Streaming Stock Data Analysis Databricks Blog
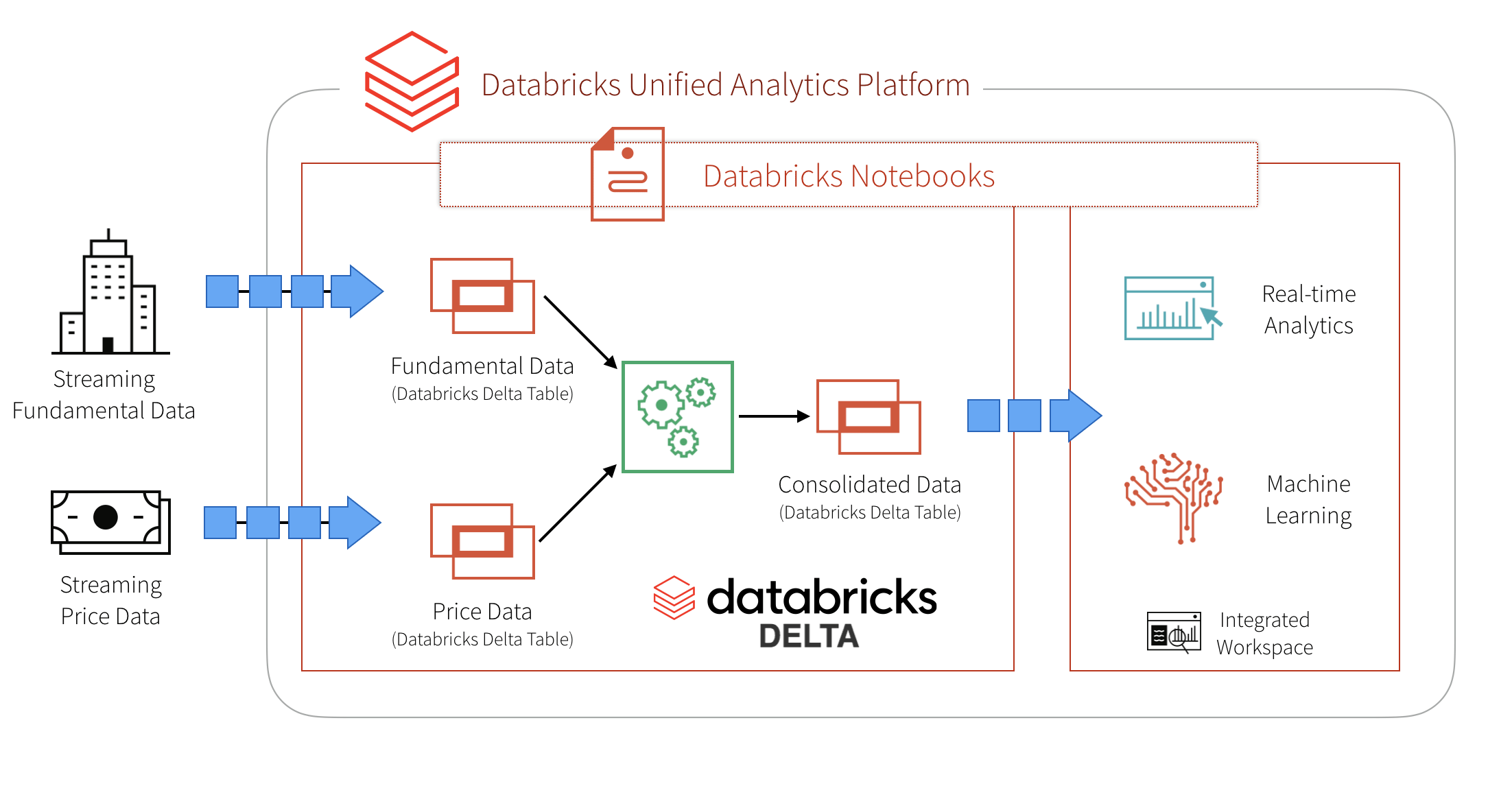
Simplify Streaming Stock Data Analysis Using Databricks Delta Databricks Blog
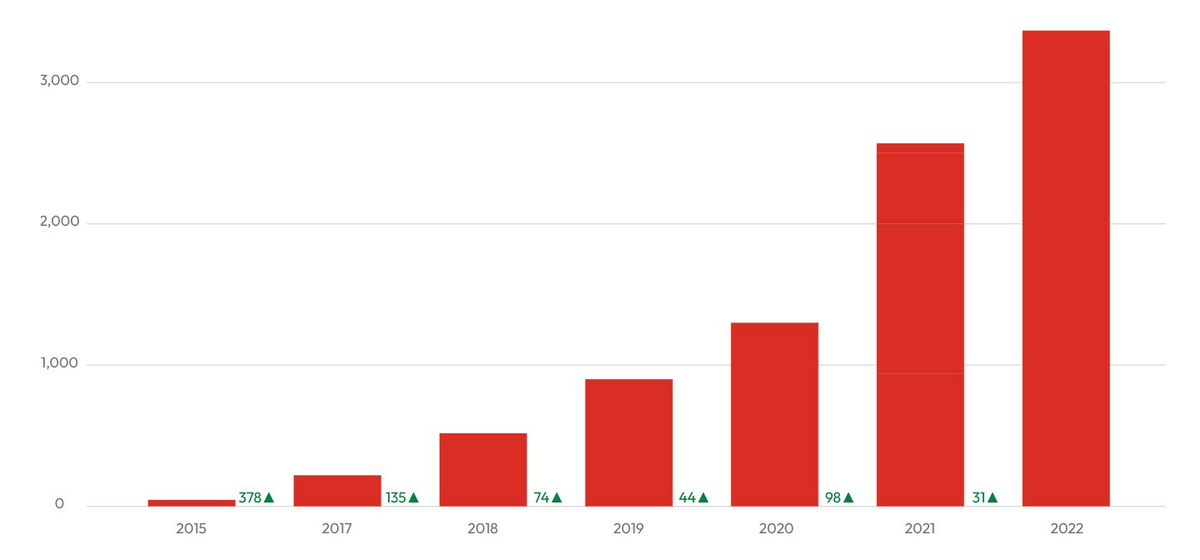
How to Buy Databricks Stock in 2025
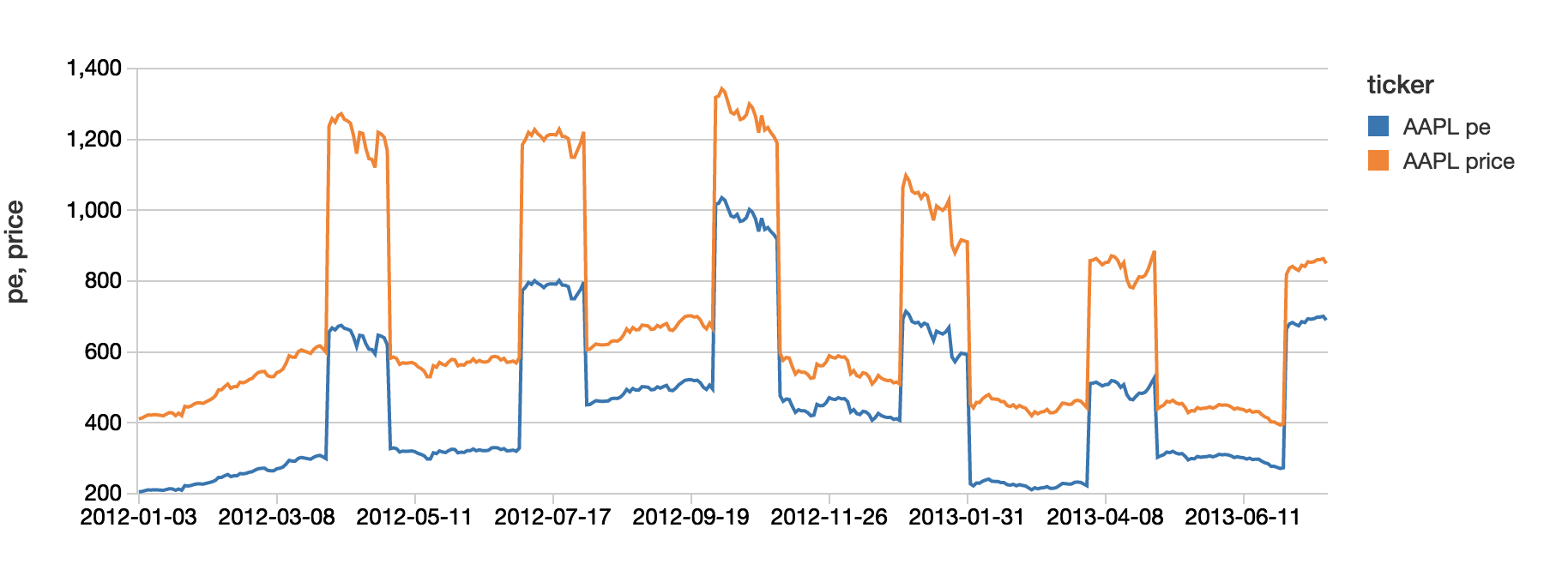
Simplify Streaming Stock Data Analysis Databricks Blog

Databricks Vantage Integrations
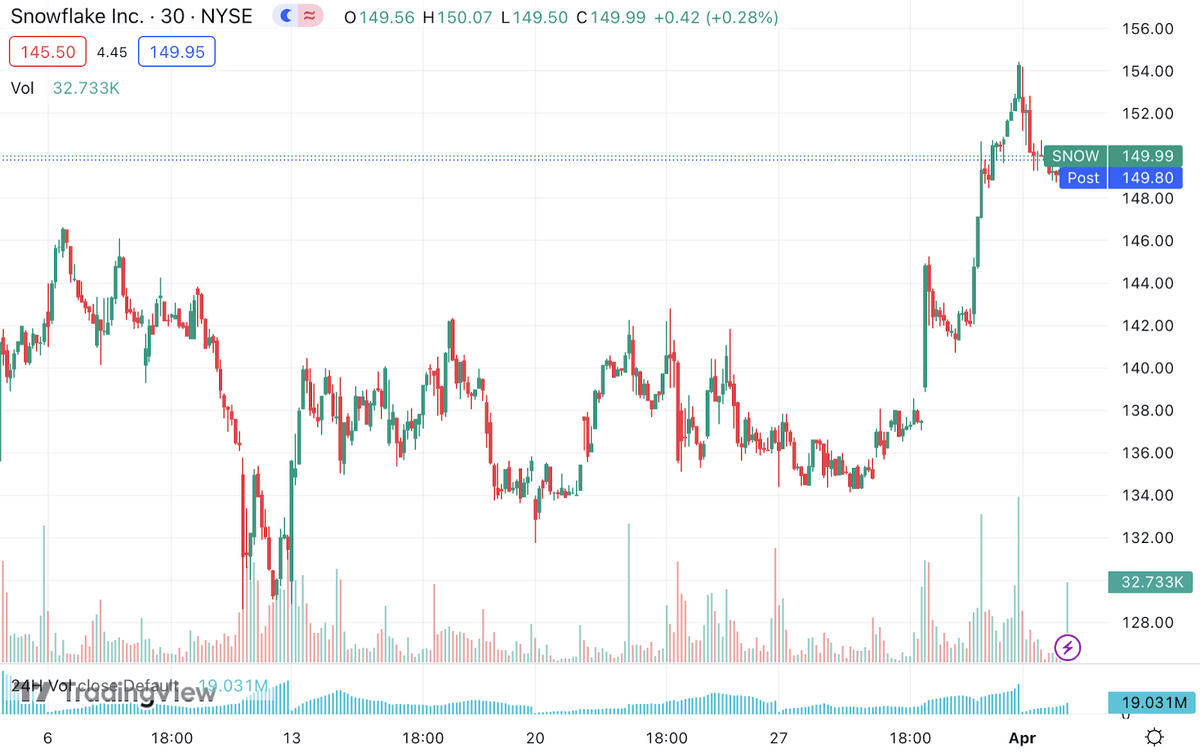
How to Buy Databricks Stock in 2025

Can You Buy Databricks Stock? What You Need To Know!
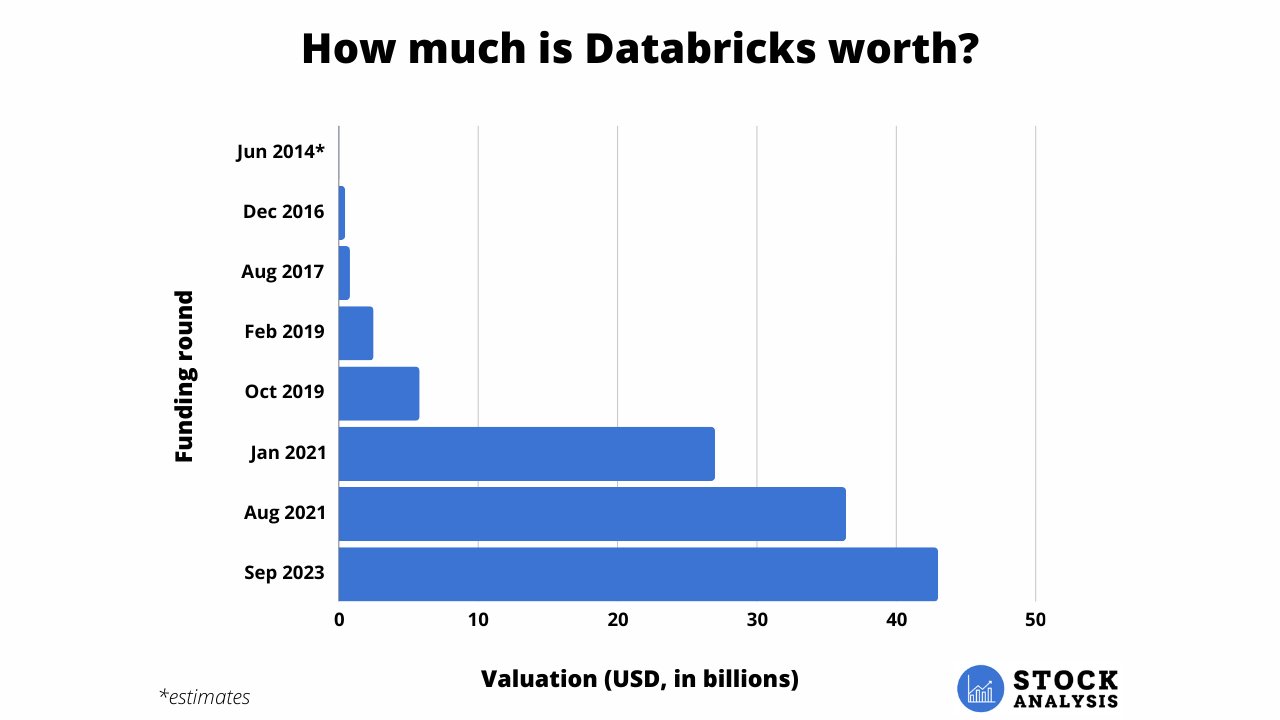
How to Invest in Databricks Stock in 2024 Stock Analysis
The Requirement Asks That The Azure Databricks Is To Be Connected To A C# Application To Be Able To Run Queries And Get The Result All From The C#.
First, Install The Databricks Python Sdk And Configure Authentication Per The Docs Here.
It's Not Possible, Databricks Just Scans Entire Output For Occurences Of Secret Values And Replaces Them With [Redacted].
I Want To Run A Notebook In Databricks From Another Notebook Using %Run.
Related Post: